Goals should fit course constraints. That includes constraints on what brains can do; goals that aren’t psychologically realistic are of little use. Goals should also be precise, so they can guide content creation.
Goal state
Let’s be explicit about what we’re trying to achieve. Here’s the situation we want at the end of the course.
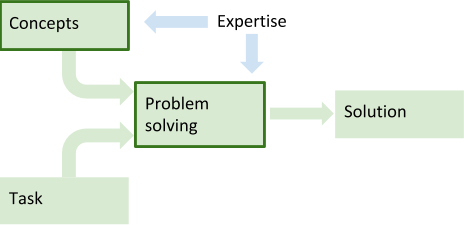
Problem solving means using concepts to complete tasks. Knowledge about concepts, and their use in problem solving, form the expertise we want students to learn.
That makes sense, but the terms “concepts” and “expertise” are too fuzzy.
Tasks
Start with tasks. “By the end of the course, students should be able to…”
- Write data analysis programs
- Design simple databases
- Whatever…
Let’s make sample tasks, along with solutions. Here’s a task for an Excel VBA course, taught to business students.
Write a program to:
- Read cheese production numbers from an Excel worksheet
- Throw out bad data (e.g., negative cheese production isn’t a thing)
- Filter data for two cheese types: Edam, and Gouda (it was the Gouda that got him)
- Compute average production for each
- Output the statistics to the worksheet
Now we have a task we can think about.
Transfer range
The cheese task is one example. We want students to be able to do any similar task. What does “similar” mean? We need more precision.
Perhaps we want students to be able to do tasks with:
- Different data sources (files, databases…)
- Different variable data types (numbers, text…)
- Various kinds of data errors (range errors, type errors…)
- Different statistics (minimum, maximum, frequencies…)
- Various output destinations (text reports, webpages…)
For each element of the cheesy task, we’ve listed variations we want students to handle. Call this the “transfer range.”
Here’s the course goal diagram again.
The course goal is coming together: give students the expertise they need to do the tasks in the transfer range.
Better, but still too vague. What is “expertise,” anyway? We need to describe the expertise that a PG course will embody.
Expertise
The “schema” is a central idea in expertise research. The term goes back to 1932, at least.
A schema is a mental rule or structure people use in their thinking. Some example schemas:
- Accumulator schema (programming): loop over a data set, add to a variable each time.
- t test schema (statistics): a way of comparing two means.
- Simultaneous equations (math): find values meeting several conditions at the same time.
Schemas are domain specific. Schemas for statistics don’t help with cooking, and vice versa. I tried braising a data set once; it didn’t end well.

Knowing schemas is a start, but students need to learn how to use them. They should be able to take a task, work out what schemas to use, and apply them to that situation. That’s the essence of problem solving.
Problem solving isn’t linear, of course. You pick schemas, start working, discover that one schema doesn’t fit, cycle back, pick a different one, try again… it’s a loopy process.
Task context guides schema choice. For example, t tests are best for interval or ratio data, with samples of 30 or more. (The sample size is just a rule of thumb.) When given a task to compare two data sets, students should know to check measurement level and sample size, before deciding on a t test.
Schemas also help people communicate. People in the same community of practice tend to know the same schemas. Suppose you’re at a party with some statisticians. One says to another, “How did that t test go?” The term “t test” means the same to both of them; they both have that schema. It also means you’re at a cool party, to have statisticians talking t.
OK, we have schemas, but students need other things. They also need procedures. To do a t test with, say, Excel, you need to know how to start Excel, set up the data, and use the T.TEST() function. While schemas are conceptual, procedures are the mechanics of using schemas to do work. Also, note that procedures like “start Excel” are used with many schemas: t tests, f tests, regressions…
Students need facts, as well. Facts are…, well, facts. For example, in programming, multiplication is done before addition, so 2 + 3 * 4 is 14, not 20. You just need to know that.
Where are we? We’re trying to be explicit about what “expertise” is, so we can set precise course goals. We’ve borrowed schemas, procedures, and facts from cognitive psychology.
Breaking down schemas
I find it helps to break schemas into categories. Other people have different categories.
Patterns
A pattern is a structure for part of a task solution. It’s the most common type of schema in my programmy world. Patterns are usually expressed in code:
- To open a file: Open filename For mode As handle
- To read CSV data into arrays: Open a file for input, for each record…
“Open a file” and “Read CSV data into arrays” are the names of the patterns. “Filename,” “mode,” and “handle” are slots. You instantiate the slots when you apply the pattern to a task. For example, maybe “file name” becomes:
ThisWorkbook.Path & "cheesy.csv".
Principles
A principle is an idea you should keep in mind when using patterns. “Make your code readable” is an important programming principle. It’s not code, but is something to keep in mind when you write code. To do it, you might:
- Use meaningful variable names
- Indent your code
- Add comments
- Break down your code into small steps
Like schemas, principles emerge from communities of practice. They’re advice a master gives to an apprentice.
Models
A model is a description of something that’s in the world. It’s a set of related facts that help understand and/or predict something.
Some models are frameworks, or taxonomies. Chemistry’s table of elements is an example. Biology’s Linnaean system (the “tree of life” thing) is another.
Some models show dynamic systems in operation. The water cycle is an example. Water evaporates, forming clouds, winds blow clouds against mountains… you know the schtick.
The examples so far have been models of natural systems, but models can be about artificial systems as well. In a programming course, how the CPU works is a model. Students can’t change it. It’s just part of the external world of the course.
Where are we?
We’re talking about what expertise is, so we can set course goals with at least some precision. We want to help students learn how to do tasks, using schemas, procedures, and facts. Schemas can be subdivided into patterns, principles, and models.
By the way, let’s use the term “concepts” to refer to “schemas, procedures, and facts.” It’s easier.
Listing the concepts needed for a course’s target tasks is a pretty good way to set course goals. We’re not quite ready to do that, however. We need to talk about constraints.
Student time limits
Many different course constraints might apply to your situation. One that’s particularly relevant to setting course goals is the amount of time students have.
Students have maybe 120 study hours for a typical semester-long skills course. That’s for readings, videos, exercises, exams, admin… everything. That’s not a lot of time for beginners to learn problem solving.
You can’t fit everything students should know into your course. Give up on that. Right now.
I can see your but-face. “But they need to know all of this! But it’s in the book! But…”
Fuggedaboutit. Human brains can only do so much in 120 hours. Accept what you can’t change.
But… you get to choose what type of incompleteness your course will have. Let’s talk about two types of incompleteness. The first one is broad-and-shallow. You jam a lot of content into the course, without giving students time to learn how to use any of it.
This is called the “coverage sin” in the understanding by design (UbD) literature. Most experts underestimate how difficult it is for students to learn what they (the experts) can do so easily. That’s the expert’s blind spot, and it explains why so many courses have more concepts than students can learn how to use.
The other type of incompleteness is narrow-and-deep. Students learn maybe 20% of the content you would like them to know. That’s not much. However, they can use that core to do a limited range of tasks.
I prefer narrow-and-deep. At the end of the semester, students can look at a real-world context (within the transfer range), and do something with it. They can build on that knowledge as well.
How many concepts should your course contain? Few enough so that students learn to use those concepts. I often underestimated learning time, despite having designed and implemented quite a few courses. My rule: “when in doubt, throw it out.”
There are other constraints, of course, like students’ limited prior knowledge (writing, math, like that), available tech, etc. However, in the academic world at least, time constraints seem to be the most difficult for professors to accept.
Goal concept list
At long last, we can describe course goals in a useful way: learning schemas, procedures, and facts needed to do tasks in the transfer range, within the time available. Woo hoo!
OK, let’s say you and your best buds have made a gnarly concept list. Now you need to make experiences to help students learn those things. How?
You can’t just give the concept list to students. That might work for experts, but students are not little experts. They’re not ready for just a concept list. They need explanations, worked examples, and other things, that create learning experiences. That’s up next.